
JBOSS MIDDLEWARE Red Hat JBoss Data Grid
IN-MEMORY DATA GRID
High performance, elastic scalability, always available
Great user experience is ever-more dependent on application performance and quality. Even a few seconds delay can mean the difference between success and failure for a new business initiative. To capitalize on customer engagement, you need to know your customers and provide targeted offers that prompt them to interact in real time. Data bottlenecks are becoming more common as organizations need to process larger volumes, greater varieties, and a higher velocity of data to meet customer expectations and deliver personalized data-driven engagement.
With Red Hat® JBoss® Data Grid—an in-memory, distributed, NoSQL datastore solution—your applications can access, process, and analyze data at in-memory speed to deliver a superior user experience.
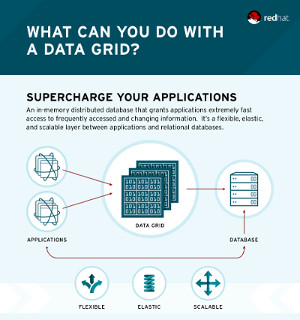
What's a data grid?
An in-memory data grid is a distributed data management system for application data that:
• Uses memory (RAM) to store information for very fast, low-latency response time and very high throughput.
• Keeps copies of that information synchronized across multiple servers for continuous availability, information reliability, and linear scalability.
• Can be used as distributed cache, NoSQL database, and event broker.
The technical advantages of in-memory data grid (IMDGs) provide business benefits in the form of faster decision-making, greater productivity, and improved customer engagement and experience.
ADOPTION DRIVERS
Modern technology trends drive adoption of in-memory data grids.
Cloud computing
• Provides elastic scale-out capabilities for a perfect fit
• Delivers better performance and scalability
• Provides option to tier data storage
Big Data
• Handles velocity, volume, and variety of data
• Integrates with Apache Spark and Apache Hadoop for analytics
Mobile
• Processes and analyzes mobile data instantly
• Handles increased workload with scalable data tier
• Provides faster, cheaper, always-on data availability
IoT
• Uses event-driven computing to process data as it's gathered
• Captures and stores IoT data streams quickly
• Analyzes IoT data in real time
Highlights of Red Hat JBoss Data Grid

Act faster
Quickly access your data through fast, low-latency data processing using memory (RAM) and distributed parallel execution.
Scale quickly
Achieve linear scalability with data partitioning and distribution across cluster nodes.
Always available
Gain high availability through data replication across cluster nodes.

Fault tolerance
Attain fault tolerance and recover from disaster through cross-datacenter georeplication and clustering.

More productivity
Gain development flexibly and greater productivity with a highly versatile, functionally rich NoSQL data store.

Stay secure
Obtain comprehensive data security with encryption and role-based access.
Database and transaction caching; transient data store
Data caching and transient data storage are the most common data grid use cases. Data grids, such as JBoss Data Grid, are deployed as a speedy in-memory datastore for the most frequently accessed data. A variation on caching is the use of data grids to store transient data (e.g., web sessions and shopping cart data, common in e-commerce applications).
You gain improved performance and scalability of the data grid-enabled applications and reduced access to expensive database management systems and transactional back ends. This often implies a reduction in the cost of running these systems.
Primary NoSQL database
Red Hat JBoss Data Grid is an in-memory, distributed, NoSQL key-value datastore that offers a simple, flexible way to store a variety of data without the constraints of a fixed data model. It can also be used as document store with the support for schema. JBoss Data Grid provides a flexible persistence model for backup, recovery, and post-processing reasons.
In addition to exploiting fast access to in-memory data, applications can take advantage of advanced functionality to perform parallel distributed workload execution, run rich queries, manage transactions, and elastically scale and recover from network or system faults.
Low-latency compute grid
Data grids bring data physically closer to data processing to reduce latency and increase application performance. JBoss Data Grid enables a scale-out architecture that deploys application logic next to the data kept in memory in each node. This is preferred over sending large sets of data to the compute nodes over the wire. This approach helps reduce network traffic significantly and increase application performance dramatically. Event-driven computing is supported by triggering application logic as data changes in the cluster.
Examples of real-time compute and analytics include fraud detection and risk management applications.
Elastically scalable, in-memory data accelerator
Data grids are well-suited to handle big data's "big 3 Vs." First, they support the velocity needs of big data. That is, data grids support hundreds of thousands of in-memory data updates per second. Second, like NoSQL datastores, data grids support big data variability. Finally, data grids can be clustered and scaled to support large volumes of data.
Similarly, the "things" in IoT all generate great volumes of data, often at more frequent intervals. JBoss Data Grid enables the storage of tens of terabytes of data, faster response times, and almost-instant analytics. This makes it feasible to process IoT data at nearly the same speed that it's generated.
CERTIFIED INTEGRATION
Use together with Red Hat JBoss Middleware
• Red Hat JBoss Fuse
Boost performance, data availability, and elastic scale for integration services. JBoss Data Grid gives you faster data storage and retrieval to implement enterprise integration patterns, service result-set caching, and offload costly back-end data systems.
• Red Hat JBoss BRMS
Store or cache fact data. JBoss Data Grid stores and caches facts data and passes these to JBoss BRMS for rules execution. Applications achieve near real-time response due to in-memory cache lookups instead of disk I/O-based database lookups.
• Red Hat JBoss Enterprise Application Platform
A primary key-value NoSQL datastore and database, offering transaction caching and transient datastore for Java™ applications hosted on JBoss Enterprise Application Platform (EAP).
• Red Hat JBoss Data Virtualization
Use JBoss Data Grid as a read/write data source and materialization target. With JBoss Data Grid, you can deliver high-performance, unified data services, and virtual data lakes using JBoss Data Virtualization's right-time data integration of disparate sources. Support business transactions, analytics, workloads, and patterns with coherent data services.

Data Interoperability support for multiple polyglot client
JBoss Data Grid enables applications written in multiple programming languages to easily access and share (read/write) data in the grid. Applications can access the data grid remotely using REST, memcached, and Hot Rod (Java, C++, .NET and Node.js).
A simple Java API also supports local access. Support for JSR-107, CDI, and Spring Cache APIs are provided for Java applications. All other application languages (e.g., Python, Ruby, PHP) are supported via popular REST and memcached protocols.
Search with a rich querying interface
Querying lets you easily search and find objects using values and ranges, instead of relying on key-based lookups or needing to know the object's exact location in the grid.

Protect your sensitive data
To support strict security requirements, JBoss Data Grid provides secured communications between client and server—and between server nodes in a secure cluster. Authentication, role-based authorization, and access control is integrated with existing security and identity structures.
With JBoss Data Grid, only trusted users, services, and applications get access.
An event-driven, distributed architecture
Event-driven processing enables real-time response to data changes throughout the data grid. The continuous queries in JBoss Data Grid are active queries that continuously re-evaluate selection criteria and automatically update the result sets based data events. JBoss Data Grid Server also supports stored tasks/scripts execution, which means that remote clients can invoke named tasks/scripts on the server based on data events, much the same way you can execute a stored procedures/triggers on a database. They are especially useful to bring data closer to compute logic (i.e., co-located in-memory for superior performance).
Simplified map-reduce parallel operations based on Java 8 stream APIs lets the developer process data declaratively and leverage multicore architecture; parallel processing many data operations on each JBoss Data Grid cluster node and then gathering the resulting elements into a data collection without the need to write any specific code for it.
Open hybrid cloud deployment
JBoss Data Grid can be deployed to support diverse IT environments with applications on-premise and in the cloud—legacy or contemporary. JBoss Data Grid can act as a data abstraction layer, decoupling the application, cache, and database.
As a result, you gain control over life cycle, maintenance, and costs of each component independently. JBoss Data Grid for xPaaS is also available as a middleware service on Red Hat OpenShift. JBoss Data Grid for xPaaS enables cloud applications running on OpenShift with in-memory speed and elastic data management.

Mission-critical, always available, and fault tolerant
With Red Hat JBoss Data Grid, applications can replicate across datacenters and achieve high availability to meet SLA requirements within and across datacenters. This allows you to implement load balancing and resource efficiency through a "follow the sun" approach.
Rolling upgrades allow JBoss Data Grid cluster upgrades with no downtime.

The content displayed on this website is sourced from the publicly available information on the websites of our principals, and is displayed here purely for informational purposes to promote our principals' products and services. All terms and conditions applicable to the content on our principals' websites remain applicable to the content displayed on the pages of www.dynamicgroup.in
Contact Us
+91 9025 66 55 66
Sales: info@dynamicgroup.in
Support: help@dynamicgroup.in
Head Office :
'Sun Flower', #355 (Old #170),
Lloyds Road, Gopalapuram,
Chennai 600086, Tamil Nadu, India.
GSTIN: 33AAGHS6671D1Z4
Regional Office :
Door No 1061, B2 & B3 TST Complex,
Avanashi Road, Coimbatore - 641018,
Tamilnadu, India.
# 57, 17th 'A' Main, HAL II Stage,
Bengaluru 560008, Karnataka, India.
GSTIN: 29AAGHS6671D1ZT
Social
About Dynamic
The Dynamic Group was founded in 1982, and has been serving customers for more than three decades now. Dynamic has, over the years, earned the reputation of being one of the most trusted and dependable organisations in the IT industry supported by impeccable standards of business ethics.Your Trusted Business Partner for Information Technology Solutions.
Hardware & Mobility
Software
Call us at +91 9025 66 55 66 to know more about our Software, Hardware & Service offerings!




